Machine learning and object detection

2018-11-17 update: you can now explore the training code along with the detection script directly on Kaggle.
Here are some great buzzwords: machine learning, artificial intelligence, deep learning… One can think of it all as something in between neural networks, mad scientists and huge computing power. Most likely what it used to be until teams at Google Brain open-sourced TensorFlow, a machine learning framework that anyone can leverage from within a Python application, or a growing selection of other programming languages.
TensorFlow has been built with a flexible architecture to allow for various use cases at any given scale. As such, one can implement scenarios like text classification on a website (“is a new comment positive or negative?”), value prediction for cities (“how is median cost of rent expected to evolve in the future?”), or even realtime image recognition (“what are the objects displayed on this video stream?”). Those are only a few “obvious” examples of the possibilities: in the artificial intelligence field, chances are we don’t even know the new use cases we are going to implement, just yet.
Let’s start our machine learning journey by making things happen based on a real-life scenario: recognizing different types of boats within images to automatically classify those images, which will ultimately help to drastically improve the indexing/searching for your library. As we won’t necessarily describe or focus on every single detail of machine learning, feel free to refer to the amazing Machine Learning Crash Course put together by teams at Google.
Retraining an image recognition model
Wait, but why re training? The answer to this question is somewhere in between not reinventing the wheel, time and cost savings. Initially, training a TensorFlow neural network from scratch will take a lot of efforts:
- gathering a tremendous amount of labeled training data, as in grouping together pictures showing persons, cars, trees, everyday objects and so many other things, then feeding those pictures grouped by categories (labels) to a neural network of your own for its initial training,
- investing in a lot of computing power, mainly CPUs and/or GPUs (yes, TensorFlow can be optimized to use GPUs) but also memory and all of the hardware and infrastructure that comes with it,
- and time to get your neural network right: it’s not like one would feed images and labels for Tensorflow to figure out alone! You have to create the model of your neural network, and it will be a very repetitive, empirical process: make a reasonable guess, train your model and see the accuracy achieved… then rinse and repeat. As your model evolves the time it takes for training expands with it: on efficient yet optimized models we are speaking about days, on hundreds of GPUs, but ultimately training time will be a factor of the dollar value you are ready to spend on the computing power you’ll put at work.
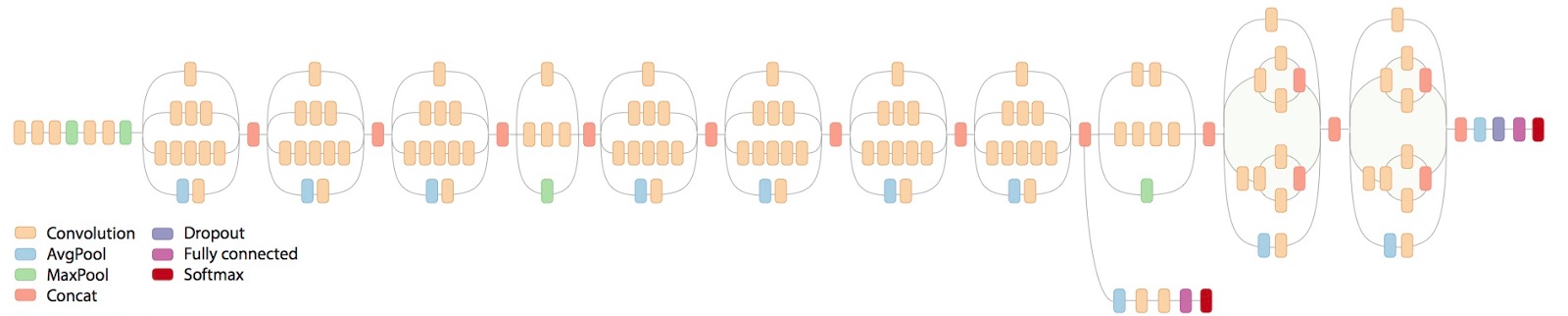
Above is a great example to summarize the complexity of an efficient neural network: this is the architecture of the InceptionV3 Pre-trained Model, able to recognize 1000 categories after being trained on 1.4 million labelled images from ImageNet. We’ll spare the efforts, go faster and make things easier by reusing this model and retraining it for our use case. On its own it will accurately recognize boats. But we will specialize it through retraining with a more granular knowledge of boat types: ferry, sailboat, freight, inflatable, cruise ship, gondola, kayak and even buoy or paper boat!
Preparing the dataset
The baseline of our image recognition model lies here: data used to train the neural network is crucial to the accuracy of the prediction that it will deliver. The more images the better, for sure, but not only. Diversity of images and precision/scope of labels/categories can drastically change the outcome of a neural network. This topic must not be lightly considered, and is so vast that I’ll rely on some great starting points to gain awareness about how to improve your dataset:
- the fairness section of the Machine Learning Crash Course by Google, and the sub-sections describing Bias
- another course by Google about Data Preparation which streamlines what the process usually looks like
- the amazing Comprehensive data exploration Kaggle notebook by Pedro Marcelino where you’ll find an extremely useful hands-on tutorial to analyze and understand your data
In our case, we’ll leverage Pixabay by downloading pre-categorized pictures from their database of royalty free stock photos. You can sign-up on Pixabay for free, and grab your API key from their API Documentation. Then, open your preferred terminal:
# reusing pre-existing, open-sourced code
git clone https://gitlab.com/clorichel/machine-learning-and-object-detection
cd machine-learning-and-object-detection
# keeping your computer clean with Docker is always a pleasure :)
docker run -it -p 6006:6006 --rm -w /ml-object-detection -v $(pwd):/ml-object-detection python:3.6.6-stretch /bin/bash
Your terminal is now attached to an interactive Docker container ready to rock’n’roll with Python. The next commands are to be run from within this container:
# install Python requirements
pip install -r requirements.txt
# feel free to explore the script documentation
python -m src.download_pixabay_images --help
# then be sure to replace the Pixabay API key with yours, and
# be ready to wait a bit for hundreds of images to download!
python -m src.download_pixabay_images --api_key TYPE_IN_YOUR_API_KEY_HERE
How convenient! Your local downloaded_images folder contains subfolders which names will be used as categories/labels, and each is filled with images that should include content related to this category.
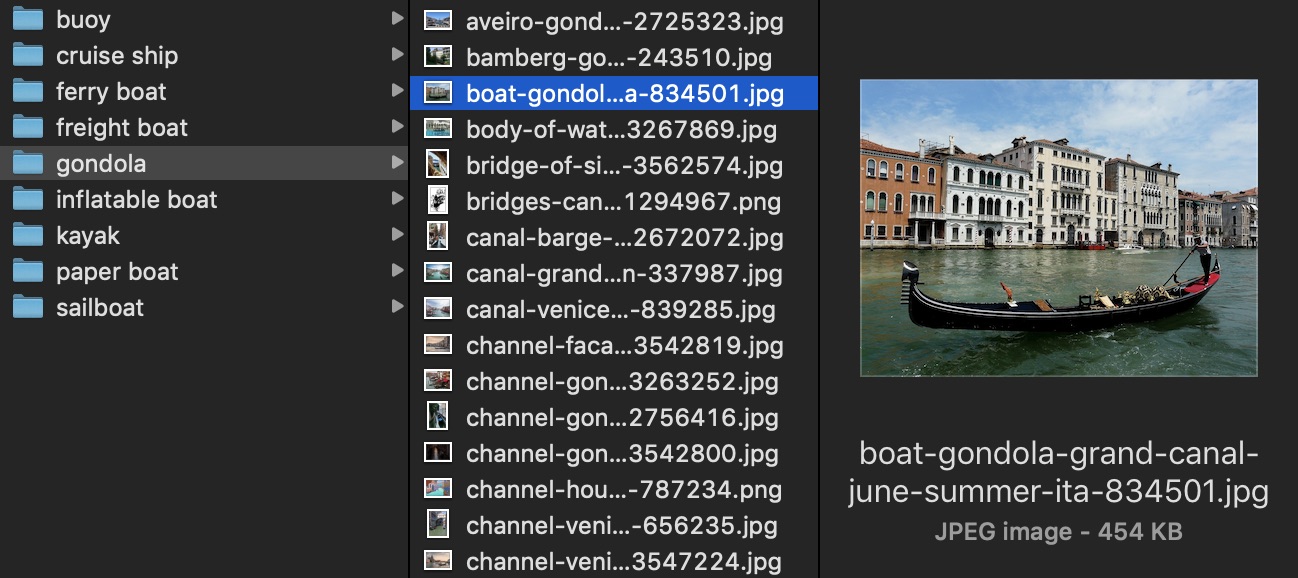
As much as Pixabay and its community is great at classifying images, you will want to take a close look at the actual images downloaded for each category. But remember to avoid Bias as much as possible! An image that could look inappropriate to you, human, might actually be very helpful for your neural network to be better at predicting a gondola. Don’t quite buy that? Experiment! You’ll be quickly convinced, and start considering machine learning as what it really is: training a neural network is about teaching a machine how to predict what something new (and never seen before) is, with an amazing accuracy.
Here is a bonus for Mac users to mass convert any PNG image in a folder to a JPG one:
for i in *.png; do sips -s format jpeg -s formatOptions 70 "${i}" --out "${i%png}jpg"; done && rm *.png
Feel free to use the curated dataset originally built for this blog post if you want to avoid both downloading and manually refining the classification of the images from Pixabay.
Retraining the neural network
Now that you’ve gathered enough images to train an existing model to recognize some types of boats, time to get TensorFlow to work. While your Python container is running (do not close it, you’ll reuse it straight away), start a new terminal and attach it to the same container:
# this one below relies on your port forward, be sure to adjust if necessary!
docker exec -it $(docker ps | grep ":6006->6006" | cut -d " " -f 1) /bin/bash
Then, from within the container, launch TensorBoard which is of great help to understand, debug, and optimize any program using TensorFlow:
tensorboard --logdir tf_files/training_summaries
Thanks to Docker port forward, you’ll be able to use TensorBoard on http://localhost:6006. Back to your original terminal, still attached to the same Python container, launch a retraining session/run:
ARCHITECTURE="inception_v3" && RUN="boats_on_inception_v3" && python -m src.retrain \
--bottleneck_dir=tf_files/bottlenecks/"${RUN}" \
--how_many_training_steps=1000 \
--model_dir=tf_files/models/"${ARCHITECTURE}"/ \
--summaries_dir=tf_files/training_summaries/"${RUN}" \
--output_graph_dir=tf_files/output/"${RUN}"/ \
--output_labels=tf_files/output/"${RUN}"/retrained_labels.txt \
--architecture="${ARCHITECTURE}" \
--image_dir=downloaded_images
With a bit of window tweaking, here is what your screen might look like in a few minutes:
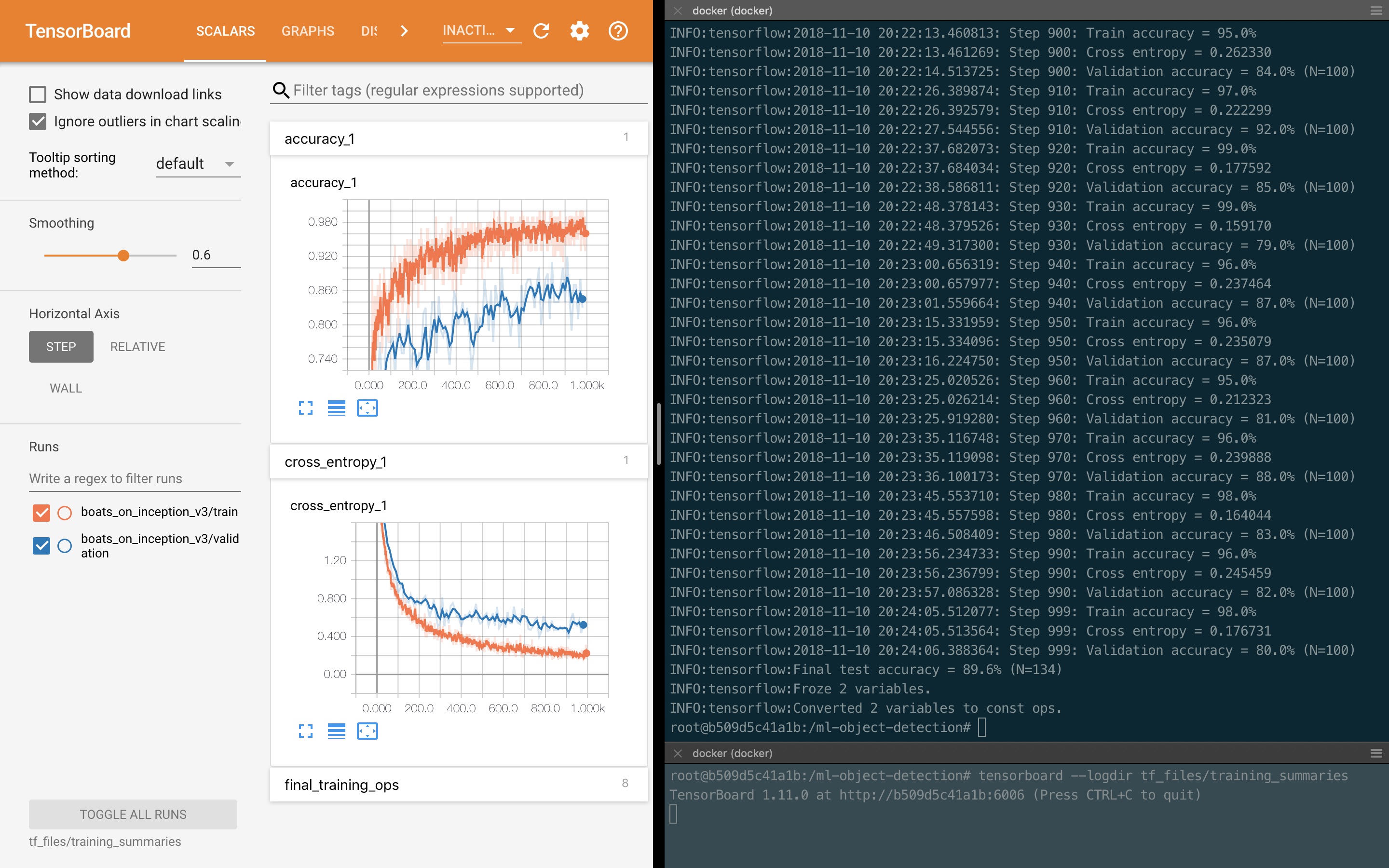
Congratulations: you’ve just retrained your first neural network! The wait to get there depends on the dataset and your computer: on a recent MacBook Pro it took about 5 minutes to create the bottlenecks for each image of a dataset with nearly 1,500 images, then approximately 10 minutes to retrain the InceptionV3 model with 1,000 steps. The result? As you can see on the screenshot above, a final test accuracy of 89.6%! What that means is, on average, if you feed 10 images containing boats to this retrained neural network, 9 of its predictions about the types of boats will be accurate.
You’ll be able to achieve an even better accuracy through different means. Expanding your dataset, ie gathering more categorized training images. Or even simpler and quicker, with more training steps: bump up the --how_many_training_steps to 2,000 or 4,000 and relaunch the training on the same dataset, the final test accuracy will get closer to 93%. An interactive example of the retraining with 4,000 steps is available on Kaggle.
Detect objects on images
In addition to the bottlenecks, training summaries for TensorBoard and the actual pre-trained model downloaded, by default the retraining script we used creates two files of interest in the output folder:
retrained_graph.pbis our neural network, it’s fully ready to recognize the various types of boats we trained it to,retrained_labels.txtcontains the labels/categories representing those types of boats.
To be sure not to test our object detection on an image that could have been used for its training, you’ll find in the examples folder a few pictures coming from Unsplash, another great source of free photos. If you’ve used the default settings mentioned in this blog post, you can test it easily from within the terminal still attached to your Python container:
# using our retrained model
python -m src.classify_image
# kayak (score = 0.97065)
# inflatable boat (score = 0.01518)
# buoy (score = 0.00708)
# paper boat (score = 0.00333)
# sailboat (score = 0.00240)
# using the original model
python -m src.classify_image --use_original --model_dir tf_files/models/inception_v3
# paddle, boat paddle (score = 0.50186)
# canoe (score = 0.12332)
# snorkel (score = 0.07753)
# bathing cap, swimming cap (score = 0.03642)
# bikini, two-piece (score = 0.01604)
Amazing! Our retrained model is 97% sure it’s a kayak, where the original model predicted it as a paddle with only 50% confidence. This is where retraining an image recognition model gets to its full potential: unprecedented accuracy to recognize the categories you are interested in.
Whether you customized some settings or want to try different example images, feel free to explore the classifying script documentation:
python -m src.classify_image --help
Again, an interactive example of the detection script running on the 3 provided images is available as a Notebook Kernel. Possibilities are now totally up to you! Use the object detection code along with your retrained model in your Django or Flask API, or integrate it within your queued workers, and get Machine Learning going for your application.
Push further with videos
That’s no secret: a video is just a set of pictures, one after the other. If you look at it that way, you are just a step from using your neural networks on videos, or even live streams! A great example by Léo Beaucourt is using OpenCV (the Open Source Computer Vision Library) to achieve object detection on videos or any video stream, including your webcam.
Similarly, Yufeng Guo developer and advocate from Google, is taking advantage of this idea by using videos both for training and predicting:
- filming various objects first, to extract pictures that he’ll then feed to the retraining,
- then using the camera from his mobile with the lightweight MobileNet, a smaller pre-trained neural network optimized for low-latency and low-power hardware like smartphones.
Have a look at the live demo he presented during Google Cloud Next ‘17:
Here are tutorials along with the code base to run a similar example: for iOS and Android. Welcome to the future!
Interested in the artificial intelligence approach and futuristic use cases? Need help putting together a team and integrating machine learning workflows in your applications?
I would love to get your feedback! Get in touch right now by email.
- Tensorflow, open source machine learning framework: https://www.tensorflow.org/
- Machine Learning Crash Course: https://developers.google.com/machine-learning/crash-course/
- Source code from this blog post: https://gitlab.com/clorichel/machine-learning-and-object-detection
- Curated dataset used on this blog post: https://www.kaggle.com/clorichel/boat-types-recognition
- Retraining Notebook Kernel on Kaggle: https://www.kaggle.com/clorichel/boat-types-retraining
- Detection Notebook Kernel on Kaggle: https://www.kaggle.com/clorichel/boat-types-detection